
Ensuring reproducible research with CODECHECK
In the following, I will introduce you to a new service for researchers at ITC called CODECHECK, "an Open Science initiative for the independent execution of computations underlying research articles to improve reproducibility" (Nüst and Eglen, 2021). For whom is this important? If you are currently working with a scripting language (e.g., R or Python) or develop an analysis that runs on data, you should continue reading.
Reproducible research refers to achieving the same results (e.g., tables, figures, numbers) as reported in the paper using the same source code and data. Since many ITC researchers publish articles that report on results based on a computational analysis, reproducible research is a relevant aspect of their work. However, several studies have shown that providing access to the underlying source code and data does not guarantee reproducibility. The analysis is often not executable or produces results that do not match those from the article. The reasons for that are manifold. To put it simply, a computational workflow that runs on your computer does not necessarily run on someone else’s computer. CODECHECK addresses this issue.
tl;dr? Just drop me message or check the video below:

The CODECHECK philosophy
CODECHECK aims to set the bar for reproducible research low for everyone. CODECHECK simply asks: "Was the code reproducible once for someone else?" For a successful CODECHECK, at least one figure or table has to be repoducible using the source code and data. The more, the merrier. I check whether the code runs and generates the expected number of output files. The contents of those output files are checked visually and available for others to see. The validity of the code is not checked.
The CODECHECK process
CODECHECK aims to increase the availability and reproducibility of computational research. All researchers at ITC who would like to check whether their source code is reproducible can request a CODECHECK. The process is as follows:
Step 1: Before you submit the manuscript for peer review or as a preprint, you provide me with access to the manuscript and the underlying source code and data. This can be done by sending me an email including a link to a public repository (e.g. GitHub or GitLab) or a private folder. At this stage, the materials do not need to be publicly available.
Step 2: I will try to execute the analysis following your written instructions on my local computer or, if possible, in the cloud, for example, using MyBinder. Then, I will check if some or all of the reproduced outputs resemble the figures, tables, and numbers reported in the manuscript. If this is not the case, we can check together if the differences are crucial and why they occur. If the code is not executable, I will notify you and ask for help and then try it again. This process can have several iterations and may result in recommendations on how to improve the code before you submit the manuscript for peer review. If you use GitHub or GitLab, I can simply make a pull request including all proposed changes (a.k.a. merge request), reducing the workload for you to a few clicks.
Step 3: In the case of successful reproduction, I will create a certificate including information on how I ran your code, what was checked, a copy of the reproduced outputs (i.e. figures, tables, and numbers), differences between original and reproduced outputs (and why they occur), and recommendations on how to improve the code. The certificate also contains a link to your source code and data. Hence, the materials need to be publicly available unless there are good reasons that speak against it (e.g., sensitive data). Please check the website of the CODECHECK initiators, which includes a list of more than 25 CODECHECK certificates.
Step 4: I will publish the certificate on Zenodo. This will allow you to cite the certificate in the supplementary materials section of your manuscript showing that you requested a CODECHECK and that it was carried out successfully. In addition, I will provide you with a CODECHECK badge (![]() ) that links to the certificate. You can add it to your repository to show that your code works. Done.
) that links to the certificate. You can add it to your repository to show that your code works. Done.
How does it look like at the end?
Certificate proving the code works (click here for the full example):

A Badge for your repository (check here):
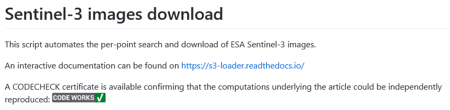
You can also add a short paragraph to the Code and Data Availability section in your paper:

When is the best time to request a CODECHECK?
At least a few days before you submit the paper for peer review or as a preprint is the best time to request a CODECHECK. This will ensure that what you submit produces the output reported in the paper. Of course, you can contact me at any time while you are working on the analysis. Please be aware that the CODECHECK might become outdated if you change the analysis during the peer review process. A CODECHECK can also be done after your paper is accepted and before it gets published. However, reviewers would not be able to consider the CODECHECK during peer review. Moreover, this would be bad timing for surprises, such as severe issues in the code that could have been found earlier. A CODECHECK after publication is possible, but again, a (positive or negative) CODECHECK result cannot be considered in the published article (unless the journal allows to edit the paper).
Who is doing all the work?
The whole process sounds like a lot of work? Don't worry! If you are running out of time, just write a bit of documentation, including a few instructions on how to run the workflow, all else I will do. All I need is access to the manuscript, the source code, and the dataset. If you want to speed up the process, please create a so-called Research Compendium. The idea behind the research compendium is to create a folder that includes all materials necessary to reproduce the results. These materials include the manuscript, the datasets, and the source code. These three components can be combined in a notebook based on the concept of literate programming. Two famous examples are Jupyter Notebooks for the programming language Python and R Markdown for R. Ideally, your code is available on GitHub or GitLab allowing me to fork the project and create a merge request to your repository. Last but not least, do not forget to add a license. If you are not sure which license to use, don’t hesitate to ask me for help.
A famous example
CODECHECK inventor Stephen Eglen did a CODECHECK on a COVID19 sumilation (a Nature paper for those who care).
What a CODECHECK is not
A CODECHECK as it is implemented here is not an official peer review unless the editor of a journal or a conference mandates me. I also cannot say whether the analysis answers your research question in a meaningful way or if the code has any hidden bugs. I am also not a statistician. Furthermore, a CODECHECK is not a replication, i.e., answering the research question with a different method or a different dataset.
FAQ
Who developed CODECHECK?
Please check: Nüst, D. and Eglen, SJ. (2021): CODECHECK: an Open Science initiative for the independent execution of computations underlying research articles during peer review to improve reproducibility. F1000Research, 10:253. DOI: 10.12688/f1000research.51738.1
Who can request a CODECHECK?
Any researcher (professor, post-doc, PhD candidate) or student affiliated with ITC and planning to submit a paper that reports on an analysis based on source code and data.
How much effort do you need to invest?
All you need to do is sending me an email with the materials. The rest is communication and we might need a short appointment to discuss issues. That’s it!
What if the CODECHECK is not successful?
No worries. The CODECHECK service is a “safe space”. If the code is not reproducible or you decide to cancel the CODECHECK, nobody will ever know. You will simply not get a certificate or badge.
Might issues with the code damage your work?
Not at all! With a CODECHECK, you show that you care about the quality, verifiability, and reproducibility of your work. That’s good scientific practice and will instead increase trust in your work.
What if you cannot publish my data due to privacy concerns?
No problem! We can use a synthetic dataset to check your analysis.
How long does a CODECHECK take?
Excluding the computation time and waiting time for the communication, a CODECHECK takes around one working day, which is similar to peer-reviewing a manuscript. The more issues the code has, the longer it will take. It also depends on your availability if issues arise. Please keep that in mind if you are planning to request a CODECHECK before a deadline.
What if you use licensed/proprietary software?
Although I strongly recommend using open-source software to ensure verifiability and reusability by others, I can perform a CODECHECK as long as I have access to the software. We can also discuss open-source alternatives before you start developing the analysis.
What if your analysis takes days or weeks to run?
No problem! We can create a data subset to reduce computation time. If a data subset does not reduce computation time, we need to check it on an individual basis considering, for example, deadlines.
How can you acknowledge my work, Markus?
Thanks for asking. You acknowledge my work already by citing the certificate associated with me and, if applicable, accepting the pull request that I will make to your GitHub/GitLab repository. I won’t mind if you mention me in your acknowledgement section 😊.
Any further questions, comments, or even ready to request a CODECHECK?
With best regards,