Greetings from the Big Geodata Newsletter!
We wish all readers a very Happy New Year! In this issue you will find information on the new Spatial Extension for DuckDB, recent query optimization efforts for Dask Expressions, the Copernicus Data Space Ecosystem and state-of-the-art global database of 2 million training points to map landcover change!
In 2024, our goal is to facilitate high interaction and community building among the users of our Geospatial Computing Platform. As part of this effort, we are set to re-introduce – Big Geodata Stories, highlighting experiences from prominent users of the platform. For this month, Dr. J. R. Bergado shared his experience of using the platform for dense point cloud extraction from UAV imagery. We believe this can help existing users benefit from each other’s experience and encourage new users to make better use of the facilities provided.
Here we also introduced you to Indupriya Mydur, who recently joined as a student assistant with CRIB. Stay tuned to our updates and newsletters in 2024, we’ve got an eventful year lined up!
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Dask DataFrame is 3x faster with query optimization!

Image credits: Coiled, 2023
Dask DataFrame is a common distributed processing tool used to work on large tabular datasets that do not otherwise fit in memory. Dask mainly achieves this by ensuring maximum resource utilization and ideal scheduling of individual tasks. The task graph hence built using the scheduler is very flexible, handling complicated queries that reach beyond SQL operations. However, until now optimizations on scheduling could not avoid tasks that are not necessary. With the recent development on Dask Expressions, high level Logical Query Planning can optimize Dask DataFrame operations to a great extent reducing the burden on developers. It reorders queries into fewer tasks, stalls computation when not necessary, drops unnecessary columns, provides improved 'merge' algorithms and overall achieves better performance using lesser memory for Dask workflows. When tested on TPC-H benchmarks that are a set of queries which are 'merge' and 'groupby' heavy, using Dask Expressions and the new P2P Shuffling algorithms sped up the runtime by 3x using far less memory!
Dask Expressions package is still under active development and not integrated into the main Dask DataFrame implementation yet. It can be installed using ‘pip install dask-expr’. The developers are keen to hear user experiences. A list of supported operations for the API can be found in the Readme.
DuckDB Spatial Extension – a new approach

Image credits: Mark Litwintschik, 2023
Recently in 2023, DuckDB, an open-source SQL OLAP (OnLine Analytical Processing) database management system designed for handling complex analytical tasks launched a spatial extension. This enables the efficiency of in-memory, multi-threaded and columnar-vectorized execution of spatial queries for not only for database files, but also GeoParquet files natively. Most traditional spatial SQL systems process each row sequentially which may lead to long run-times on large datasets, but DuckDB can do the same work almost instantly. Built on foundational geospatial libraries (GEOS, GDAL and PROJ) the DuckDB Geometry type can handle a range of SQL functions like ST_Area, ST_Intersects and ST_Transform along with methods for reading, writing of over 50 geospatial formats. The project also introduces a set of non-standard specialized columnar DuckDB native Geometry types that aim to provide better compression and faster execution in exchange for some flexibility. Ongoing developments in columnar-vectorized query execution are geared towards significantly improving the performance of Spatial Joins through the implementation of efficient data partitioning strategies.
For starters, an open-courseware on Spatial DuckDB by Dr. Qiusheng Wu is a useful resource. Blog posts by Chris Holmes and Mark Litwintschik give insights into the kind of use cases Spatial DuckDB would be ideal.
Copernicus Data Space Ecosystem
Image credits: Copernicus EU, 2023
The Copernicus Data Space Ecosystem is new service to better access and exploit the EU's Copernicus satellites data. The service, which is designed for scalability and user-friendliness, aims to be the go-to platform for extracting insights from Copernicus data, ensuring flexibility, adaptability, and continuity with existing distribution services. It provides a wide range of services, including catalogue APIs for product download, web services for data processing such as openEO and Sentinel Hub APIs, the Data Workplace to generate Earth observation products on demand, the Traceability service for the complete tracing of a data product's integrity from its origin to its download, the JupyterLab service to immediately start working with the available data and APIs without the need to download any data, and finally the openEO Web Editor that provides an easy-to-use interface to the available datasets and processes.
The Copernicus Data Space Ecosystem is a step forward for empowering users to unlock the full potential of Copernicus satellite data. If you like our Geospatial Computing Platform, probably you will like the Copernicus Data Space Ecosystem as well, which is available for free. Check it out!
Upcoming Meetings
- EGU 2024
14-19 April 2024, Vienna, Austria - GeoAI and Earth Observation Advances and Future Trends
Special Issue, Submission deadline: 30 April 2024 - GEOINT 2024
5-8 May 2024, Florida, USA - Geospatial World Forum
13-16 May 2024, Rotterdam, Netherlands - AGILE 2024, Geographic Information Science for a Sustainable Future
4-7 June 2024, Glasgow, UK - IEEE International Conference on Big Data Computing Service and Machine Learning Applications
15-18 July 2024, Shanghai, China - Big Data Expo
11-12 September 2024, Utrecht, Netherlands

Recent Releases
- CuPy: NumPy/SciPy-compatible Array Library for GPU-accelerated Computing
12.3.0 (07/12/2023) - PyTorch: Machine learning framework based on the Torch library
2.1.2 (15/12/2023) - OpenCV: End-to-end machine learning platform
4.9.0 (28/12/2023) - GeoPandas: Python tools for geographic data
0.14.2 (04/01/2024) - GeoTrellis: Geodata processing library to work with large raster data sets
3.7.1 (08/01/2024)
The "Big" Picture
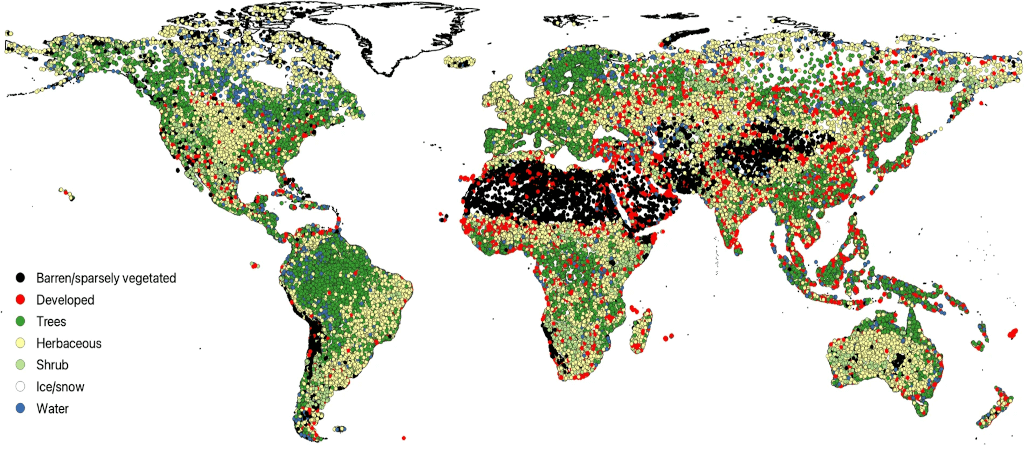
Image credits: Stanimirova et al., 2023
A large group of researchers have developed a global database of nearly 2 million training units spanning 1984 to 2020, aimed at enhancing regional-to-global land cover and change mapping. Leveraging Google Earth Engine and machine learning algorithms, the project team efficiently sampled spectral-temporal features from Landsat imagery, ensuring data quality and biogeographic representation. The dataset, strategically augmented to reflect regional class distribution and post-disturbance landscapes, underwent a machine learning-based cross-validation process to eliminate potential mis-labeling. The dataset is not only useful land cover mapping but also holds significant value for studies in agriculture, forestry, hydrology, urban development, and more. The dataset's potential applications across diverse fields make it a beacon of innovation and collaboration in the intersection of technology, machine learning, and ecological research.
Stanimirova, R., Tarrio, K., Turlej, K., McAvoy, K., Stonebrook, S., Hu, K.-T., Arévalo, P., Bullock, E. L., Zhang, Y., Woodcock, C. E., Olofsson, P., Zhu, Z., Barber, C. P., Souza, C. M., Chen, S., Wang, J. A., Mensah, F., Calderón-Loor, M., Hadjikakou, M., … Friedl, M. A. (2023). A global land cover training dataset from 1984 to 2020. Scientific Data, 10(1), 879. https://doi.org/10.1038/s41597-023-02798-5