Greetings from the Big Geodata Newsletter!
In this issue you will find information on the SpatioTemporal Asset Catalog (STAC) specification, LotusSQL which is the SQL engine for high-performance big data systems, GEE Timeseries Explorer for QGIS, and a “big picture” on using video compression methods to store high-dimensional spatiotemporal data! Our regular upcoming events, recent releases, and CRIB news sections are here as well. We have also a short survey on our upcoming JupyterLab use cases workshop!
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
STAC: Easy Gate for Publishing Geodata
 Image credits: stacspec.org, 2021
Image credits: stacspec.org, 2021
The SpatioTemporal Asset Catalog (STAC) aims at building a new search engine to ease the process of retrieving geospatial information, especially for big data sets, while maintaining the best web-based access practices. The STAC specification provides a JSON wrapper for EO data. The GeoJSON core and related structures were designed for adaptability at various application domains. When used in concert with formats like Cloud Optimized GeoTiff or TileDBarrays, one expects vast improvement of the searching and rendering speed for geospatial and EO data.
STAC is composed of four semi-independent elements. Each of them can function alone but works better synchronically. STAC item forms the fundamental unit to represent a single spatiotemporal asset, STAC Catalog is a JSON file of links that organise and browse STAC items, STAC Collection extends the information for STAC Catalog, and STAC API functions as the endpoint enabling search of STAC items. Currently, several catalogs are readily available, such as Landsat, CBERS, Sentinel 2, Google Earth Engine, Spacenet, ISERV, and Sentinel Hub. There are also a variety of tools available to further enhance STAC functionalities, such as Rockt - a STAC client for browsing public STAC Catalogs, PyTAC - an interface to STAC via Python, and EODAG - a Python framework for searching, aggregating results and downloading EO data. If you are interested in participating in the STAC project, there are several channels open for volunteers.
LotusSQL
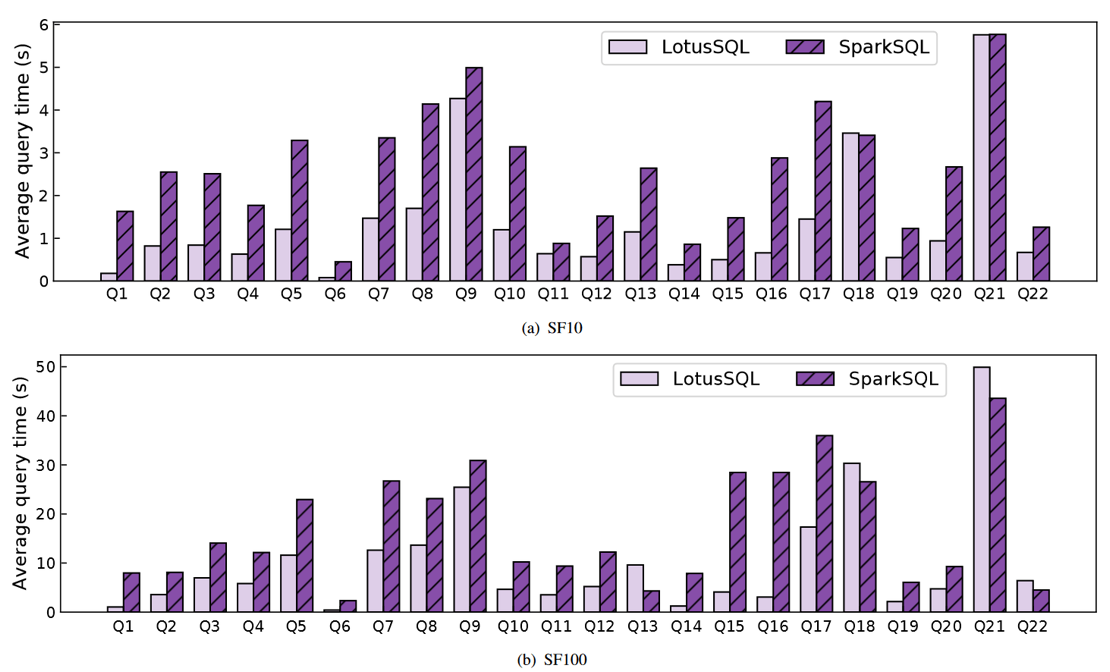 Image credits: Li et al., 2021
Image credits: Li et al., 2021
In recent years, Apache Spark has become a powerful tool for big data processing. SparkSQL is a module offering support for relational analysis on Spark with Structured Query Language (SQL). Although SparkSQL provides convenient data processing interfaces and has an efficient optimizer, it still suffers from inefficiencies due to the Java Virtual Machine and unnecessary data serialization and deserialization. Adopting native languages like C++ would help avoid such bottlenecks and this is exactly what LotusSQL has achieved.
LotusSQL is an engine that provides SQL support for dataset abstraction on a native backend Lotus. The backend is a single-machine data-parallel computing engine constituted by a low-overhead storage module and a highly efficient compute module. The frontend is implemented by extending Calcite and entails parsing a given SQL query into a logical plan which is then optimized to produce a physical plan of execution. Afterwards, the physical plan is mapped into C++ codes of structured data operations by the code generator, the codes are run on the backend, and results are collected. Test results show that LotusSQL achieves a speedup of up to 9x in certain queries and outperforms Spark SQL in a standard query benchmark by more than 2x on average.
Li, X., Yu, B., Feng, G., Wang, H., and Chen, W., 2021, LotusSQL: SQL engine for high-performance big data systems, Big Data Mining and Analytics, 4(4):252-265, https://doi.org/10.26599/BDMA.2021.9020009
Upcoming Meetings
- Get started with Dask with a hands-on tutorial, 6/10/2021, Online
(Registration) - Geospatial World Forum 2021, Theme: Geospatial Infrastructure & Digital Twin, 20-22/10/2021, Amsterdam
(Call for Papers - Deadline 30 June) - Spatial Data Science Conference, 25-28/10/2021, Online
(Submit your talk) - Enabling Copernicus Big Data Analytics through European Open Science Cloud, 27/10/2021, Utrecht
(Program & registration) - ESA-ECMWF Workshop on Machine Learning for Earth System Observation and Prediction, 15-18/11/2021, ESA-ESRIN (Italy), Hybrid
- 10th Geo for Good Summit, 16-19/11/2021, Online
(Apply now)

Useful Tools: GEE Timeseries Explorer for QGIS
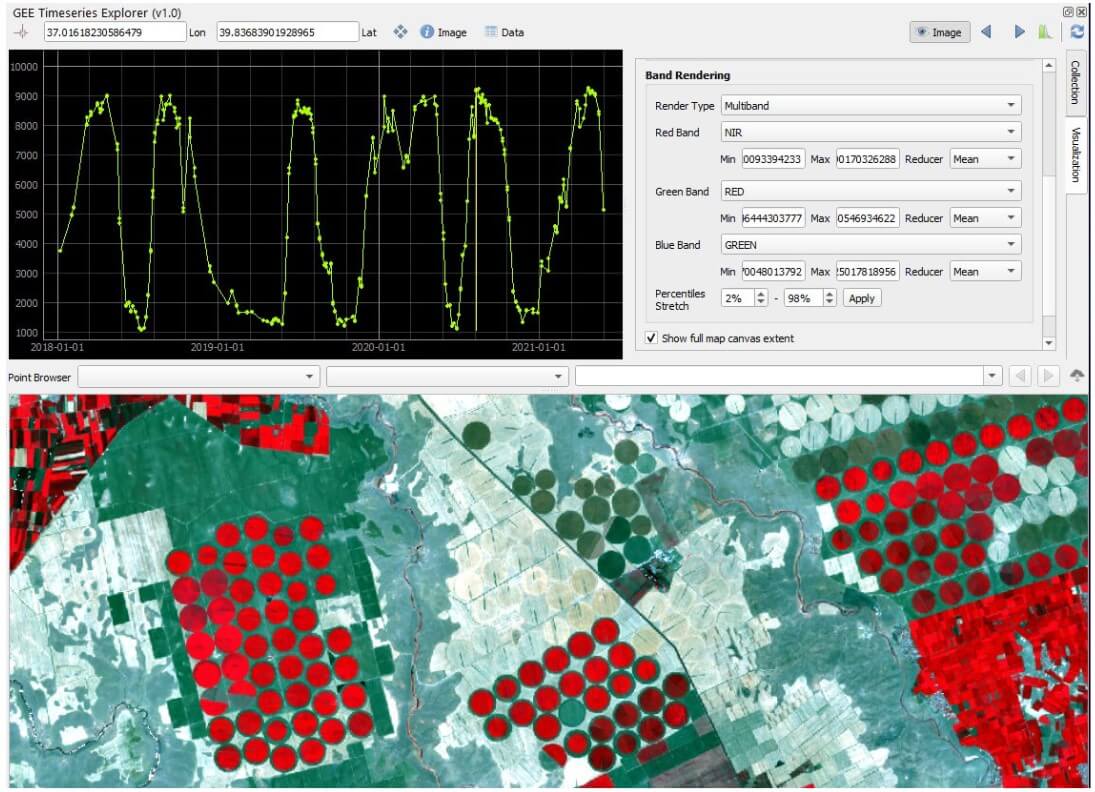
Image credits: Rufin et al., 2021
Google Earth Engine (GEE) leverages the accessibility to multiple satellite image sets to make easy the analysis of time series. However, the lack of an instant visualisation tool for the time-series data impedes its utility. GEE Timeseries Explorer was designed to fill in this gap. It is a QGIS plugin that grants instant access GEE inside QGIS (≥ 3.16) with your GEE account.
GEE Timeseries Explorer offers flexible integration of any GEE image collection. Upon loading a collection, users can select single or multiple bands to perform time-series query. The data is retrieved in raw format and is instantly visualised via PyQTGraph. The plots can be manipulated interactively, such as adjusting layout options or axis scaling. Individual images of the time series can be visualised by selecting specific points on the plot. The retrieved image as a WMS layer can be added to the QGIS layer panel upon request. Users can also download data series from the interface.
Survey: JupyterLab for education and research
 Image credits: CRIB, 2021
Image credits: CRIB, 2021
We conducted an introduction to JupyterLab workshop on 7 September. It was very encouraging to see 70+ participants for the event. During the workshop, we received a lot of constructive feedback from you. In response, we would like to prepare another workshop more tailored for JupyterLab use cases for geospatial and EO data analysis, with a special focus on education. In order to better customise the upcoming workshop, we would appreciate your input by filling out this short survey.
Thanks!
Recent Releases
- Albumentations: Fast image augmentation library
1.0.3 (2021/07/15) - Breeze: Numerical processing library for Scala patterned after NumPy, Matlab and R
13 (2021/08/14) - Open Data Cube: Open-source Geospatial Data Management and Analysis
1.8.5 (2021/08/18) - scikit-learn: Machine learning in Python
1.0 (2021/09/24) - oracle_fdw: PostgreSQL Foreign Data Wrapper for Oracle
2.4.0 (2021/09/24)
The "Big" Picture
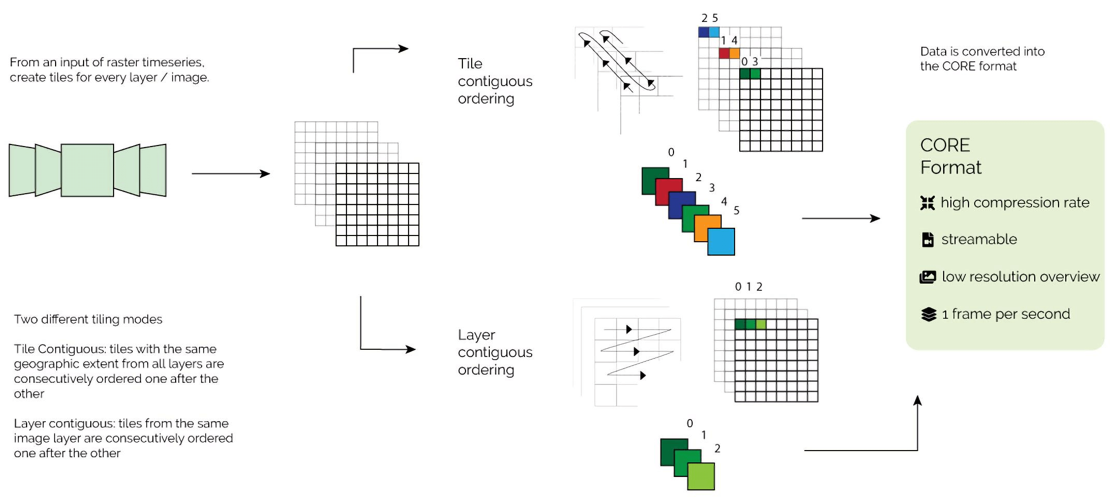 Image credits: Enescu et al., 2021
Image credits: Enescu et al., 2021
Data cubes that store high-dimensional spatiotemporal data in the manner of stacking time sequence of spatial panels gained more attention and popularity with the growing availability of open geospatial data. In the context big data, this data organisation approach presents a great challenge for its need of large physical storage space as well as slow rendering on the web. To address these issues, a new Cloud Optimized Raster Encoding (CORE) format was developed to enable an efficient storage and management of gridded data by applying video encoding algorithms. Specifically, CORE was built on top of three technical pillars, i.e. (a) reducing spatial redundancy between time frames, (b) encoding and decoding algorithms to compress gridded data, and (c) support of HTML5 for efficient streaming.
In order generate CORE format, it only needs two consecutive operations contingent solely on open-source software. First, raw geodata files are divided into smaller tiles using tools like GDAL. Second, the resultant tiles are organised into video using FFmpeg. Constant Rate Factor (CRF) is an option to control the video quality after compression, ranging from 0 (lossless) to 23. According to the authors’ research, very efficient compression was achieved with H.264 video codec and the output images with CRF up to 18 (about ¼ of the original size) bore nearly no noticeable difference from the original judging by human eyes.
Iosifescu Enescu, I., de Espona, L., Haas-Artho, D., Kurup Buchholz, R., Hanimann, D., Rüetschi, M., Karger, D.N., Plattner, G.-K., Hägeli, M., Ginzler, C., Zimmermann, N.E., Pellissier, L., 2021, Cloud Optimized Raster Encoding (CORE): A Web-Native Streamable Format for Large Environmental Time Series, Geomatics, 1:369-382, https://doi.org/10.3390/geomatics1030021