Greetings from the Big Geodata Newsletter!
Greetings from the Big Geodata Newsletter! In this issue you will find information on Φ-week - ESA's annual event dedicated to innovation in EO, cuGraph - large-scale graph analytics on GPUs, Thrill - a high-performance C++ framework for distributed computing, and a new settlement dataset for U.S. which goes back to 1800's at fine spatial resolution! Our regular upcoming events, recent releases, and CRIB news sections are also there. Happy reading!
If you find the newsletter useful, please share the subscription link below. You can access the previous issues of the newsletter on our web portal.

First waves of OCRE Cloud Funding for Research targetting individual researchers and Earth Observation Services Funding for Research targetting research projects at individual institutes (e.g. ITC) are open for submission with deadlines of 2 November and 30 November, respectively. Both calls aim to support 100% of the consumption of the cloud services up to 100,000 EUR.
Microsoft Azure, which is the cloud service provider of UT, is one of the awardess of the OCRE framework for cloud services and they are open to provide support to the interested ITC researchers in quantifying cloud service needs or designing cloud-based analysis workflows. For more information, you can contact Ralph Mettinkhof (UT-LISA).
ESA EO Φ-Week

Image credits: ESA, 2020
Φ-week, ESA's annual event focusing on innovation in EO with showcases on the latest developments in EO science, technology, and applications took place in the last week of September. As the new "norm", the event was fully virtual, including coffee breaks and networking sessions. This year's topic was Digital Twin Earth - an AI-driven digital replica of our planet to enable science-based decision capabilities, enhanced predictions, and simulations to respond societal and environmental challenges by using cloud computing, modelling, AI, and global-scale big data.
If you missed the event, you can watch the recorded sessions at ESA's Vimeo channel dedicated to the event. Here is a short list which you may find interesting (check the complete programme for more):
- Opening Session
- Infrastructure for Digital Twin Earth
- AI for Digital Twin Earth
- Digital Twins Experiences in the World
- ESA DTE Precursor Activities
Upcoming Meetings
- Geo for Good Summit 2020 (Virtual Event), 20/10 - 22/10/2020
(Agenda, Check-in) - BigSpatial 2020: 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, 03/11
(Check also 28th ACM SIGSPATIAL 2020 Virtual Conference) - AI & Big Data Expo Europe 2020 (Virtual Event), 23-24/11/2020
(Agenda, Registration) - IEEE BigData 2020 (Virtual Event), 10/12 - 13/12/2020
(Registration - early bird rate until 15 November)
GPU-accelerated Graph Analytics: cuGraph

Image credits: Rees, 2000
Graphs are very simple data structures composed of only edges and vertices. But they can be very difficult to deal with, especially if they are big (e.g. millions of edges). In fact, such graphs are common in many geospatial problems and they are getting bigger and bigger (lucky us!). Although well-developed frameworks exists to help computation on CPUs, GPU-based solutions started to shine with their performance as shown in the table above. cuGraph is one of these libraries, which provide both low-level (C++) and high-level (Python) access to GPU-accelerated graph algorithms. The library supports both directed and undirected graphs, and features a long list of algorithms, some of which can be scaled easily to multiple GPUs. It is also compatible with existing graph libraries (e.g. NetworkX) and can be used as drop-in replacement in many cases. You can find more information on this compatibility and real-world benchmarks in this Medium post.
If you have access to a GPU with NVIDIA Pascal architecture or better with CUDA 10.1+ support, you can start testing cuGraph by using the latest rapidsai Docker image. No worries if you don't have one, CRIB's computing cluster with NVIDIA Jetson AGX Xavier units will be at your service pretty soon!

Thrill: Distributed Big Data Processing in C++
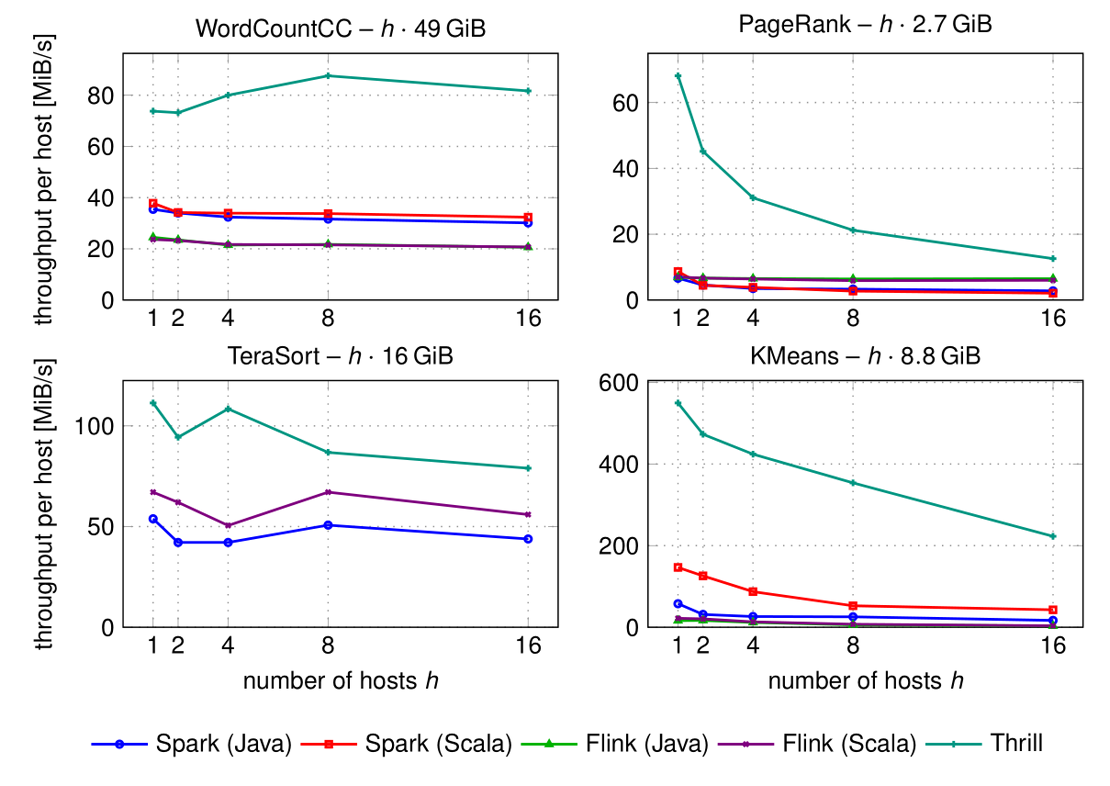
Image credits: Bingmann, 2000
Commonly used big data computing frameworks are usually based on interpreted languages (e.g. Java, Python) and have significant processing overhead leading to high memory consumption and long processing time. Can it be possible to have a better performance by using frameworks based on compiled languages without compromising flexibility? Well, benchmarks say yes!
Developed by Bingmann et al. at the Karlsruhe Institute of Technology, Thrill is a general purpose, high-level, easy-to-use C++ framework to implement distributed algorithms. Focusing on high performance, the framework enables applications to process small datatypes efficiently without overhead, avoid unnecessary data serialization/deserialization (i.e. round trips to memory or disk), perform full pipelining of data flows, and run directly on hardware without an interpreter.
A detailed tutorial video is made available recently, which contains introduction to parallel computing, presentation of the framework, and live-coding sessions with example use cases. It is long (close to 3 hours!), but table of contents is available to jump to specific topics (e.g. k-Means). You can also read the full transcript or check the slides.
Recent Releases
- rasterio: Python raster API based on Numpy N-d arrays and GeoJSON
1.1.7 (2020/09/29) - Microsoft R Open: Enhanced R distribution for multi-threaded computations
4.0.2 (2020/09/23) - CGAL: C++ library for efficient and reliable geometric algorithms
5.1 (2020/09/08) - Horovod: Distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet
0.20 (2020/09/04)
the "Big" Picture
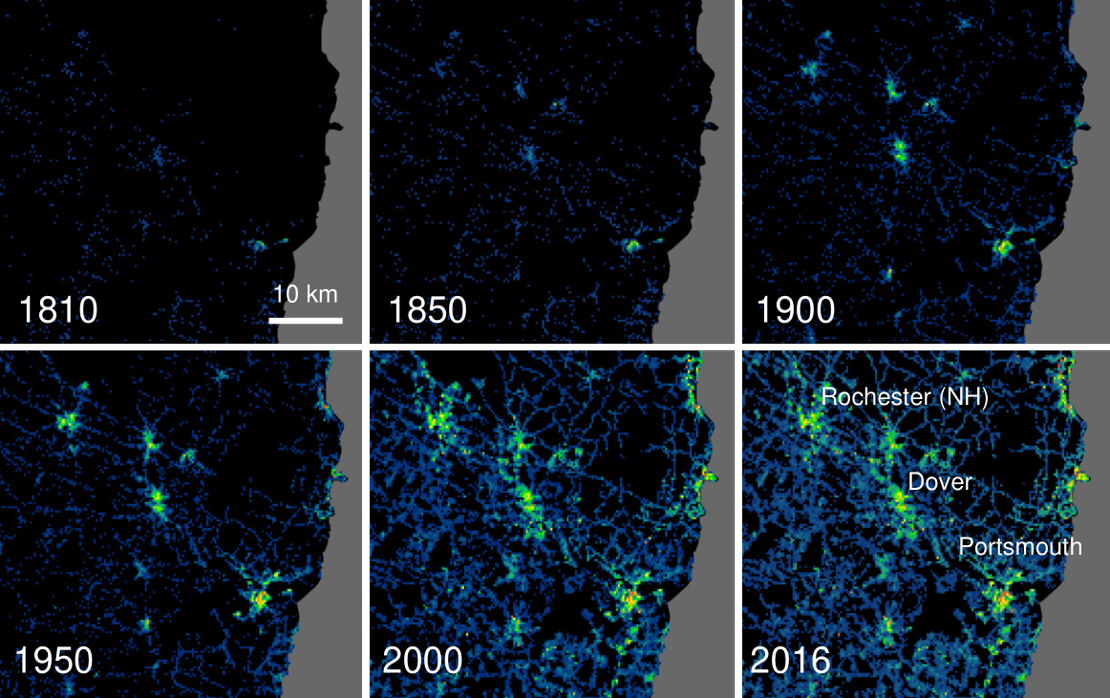
Image credits: Uhl et al., 2000
We are in a "boom" period of high-resolution global studies thanks to cloud-based computing platforms with planetary-scale analysis capabilities. However these studies are usually limited to 40 years, for which long-term EO data is publicly (and easily) available. Uhl et al. push the limits by constructing new spatially-explicit settlement data for the United States that extend back to the early nineteenth century at fine spatial (250 m) and temporal (5-year interval) resolution. The Historical Settlement Data Compilation for the United States (HISDAC-US) contains historical gridded settlement layers derived from property records compiled in the Zillow Transaction and Assessment Dataset (ZTRAX). The dataset include layers of the number of built-up property records, built-up intensity, the first built-up year, and the built-up area, which can be used to understand the speed, spread, and nature of urbanization in the United States from 1810 to 2015.
Uhl, J. H., Leyk, S., McShane, C. M., Braswell, A. E., Connor, D. S., and Balk, D.: Fine-grained, spatio-temporal datasets measuring 200 years of land development in the United States, Earth Syst. Sci. Data Discuss., https://doi.org/10.5194/essd-2020-217, in review, 2020.