Greetings from the Big Geodata Newsletter!
In this issue you will find information on applications of spatial data cubes, eScience Center-ITC collaboration on large-scale phenological modelling, recent developments in GPU-accelerated distributed computing, our new web portal, a tool to extend spatial analysis capabilities of key-value databases, and a new method to fill gaps in earth observation data implemented in the cloud. Happy reading!
If you find the newsletter useful, please share the subscription link below. You can access the previous issues of the newsletter on our web portal.
Spatial Data Cubes
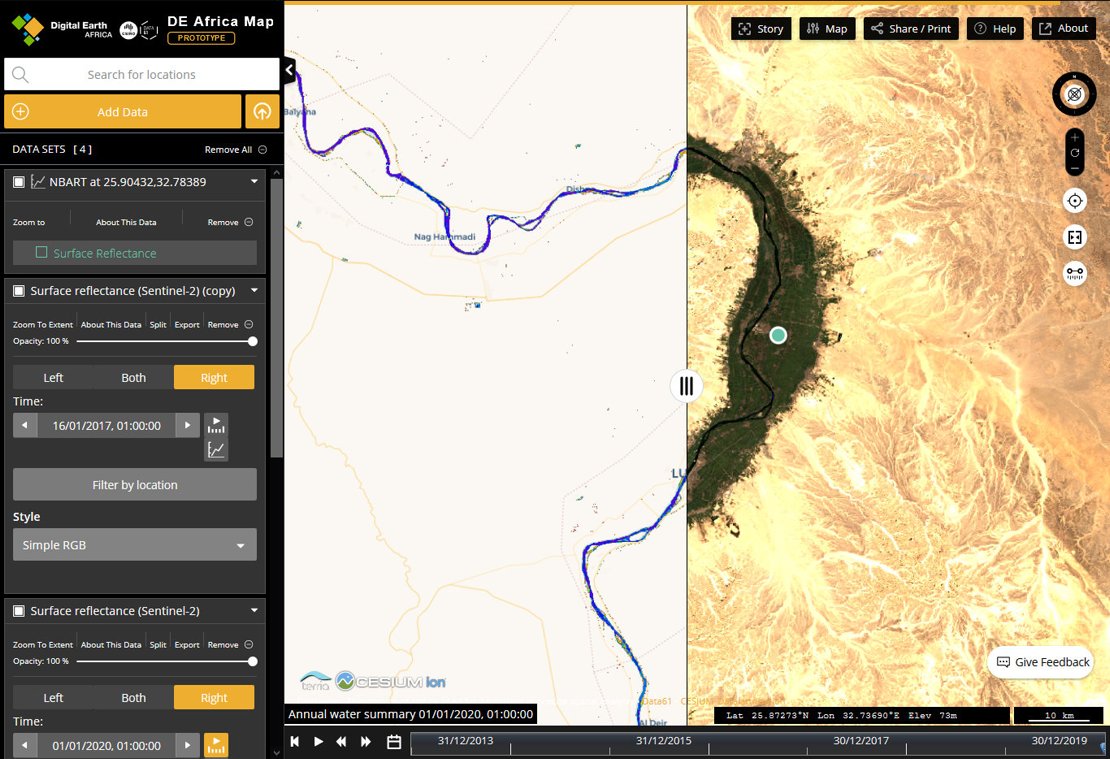
Large amounts of Earth observation data become available each day and the infrastructure needed for analysis is also getting easily accessible thanks to the recent developments in cloud technology. Still, indexing, querying, and analysing big geodata sets are challenging tasks which require the use of a large stack of software tools and quite frequently involve significant customization. Unless you use a spatial data cube designed to streamline the work!
Open-source solutions are available to set up and operate data cubes. Open Data Cube, which is an OSGeo project, is one of such systems that is field-proven in Digital Earth Australia and Digital Earth Africa projects. Currently the technology is more data-management oriented and relies on the capabilities of the base libraries for spatial analysis with limited distributed computing possibilities. However, the progress is rapid and promising.
"Leveraging Advanced Technologies - Focusing on Data Cubes" session of the recent GEO Virtual Symposium 2020 that took place on 15-19 June was devoted to example data cube applications world-wide, including Europe, Africa, Australia, and Latin America. Recordings of the live session and also individual presentations are available here
ITC Big Geodata infrastructure will provide a data cube with analysis-ready data, which you can use to experiment with the technology. Stay tuned!
eScience Center - ITC collaboration on large-scale phenological analysis

Image credits: Marc Schloesser, Wikimedia
.jpeg){kind=link}
In 2016, ITC and the Netherlands eScience Center set an alliance for high-resolution phenological modelling at continental scale, which resulted in the development of a cloud-based analysis platform. Recently, the collaboration has been extended to explore the performance of different distributed computing platforms, namely Apache Spark and Dask, for large-scale phenology studies. The study, which can also provide quite useful information (e.g. performance metrics) for other big geodata problems, will be supported by the Center of Expertise in Big Geodata Science (CRIB).
For more information, you can read the post by the eScience Coordinator Dr. Yifat Dzigan or contact Prof. Dr. Raul Zurita-Milla (GIP-ITC).
Apache Spark meets GPU
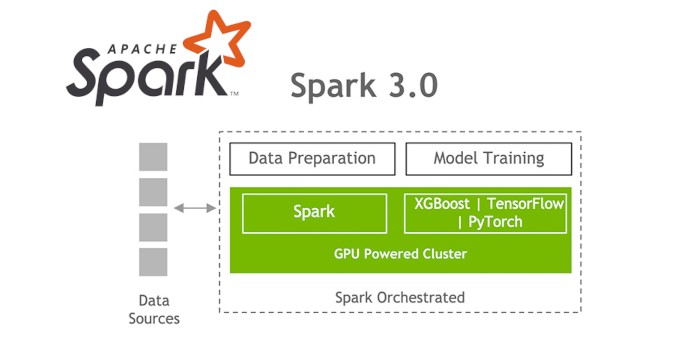
Apache Spark is currently one of the leading general purpose cluster computing frameworks for large-scale data processing. Besides providing APIs in Scala, Java, Python, and R, it also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing. For geospatial analysis, well-developed libraries exist which extend its capabilities, such as GeoSpark, GeoMesa, GeoTrellis, and Rasterframes.
Until recently Spark was mainly limited to CPUs for processing. In addition to important performance improvements (e.g. up to 40x speed-ups for calling R user-defined functions), the new version Spark 3.0 announced in June now supports native accelerator-aware scheduling to take advantage of GPUs. This feature allows GPU-accelerated workloads for highly parallel and computationally intensive machine learning and deep learning applications. If you want to pioneer the technology for geospatial problems, it is the perfect timing, because it is currently available in early access. This nice book from NVIDIA (sign-up required) can provide you all the information needed!
CRIB web portal is online

The Big Geodata Newsletter not only aims to keep you informed on the developments in the field, but also on the activities of CRIB in general. Now we have additional media for the latter! The primary one is the web portal available at https://itc.nl/big-geodata. On the portal you can find information about CRIB, the on-going projects, and more news and events. All issues of the newsletter are also accessible.
In addition to the web portal, our Twitter account (@BigGeodata) allows us to keep connected with the community and share more on the big geodata technology!
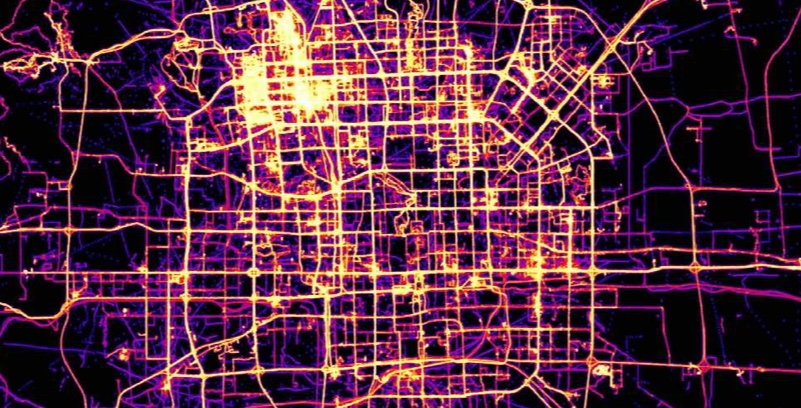
GeoWave
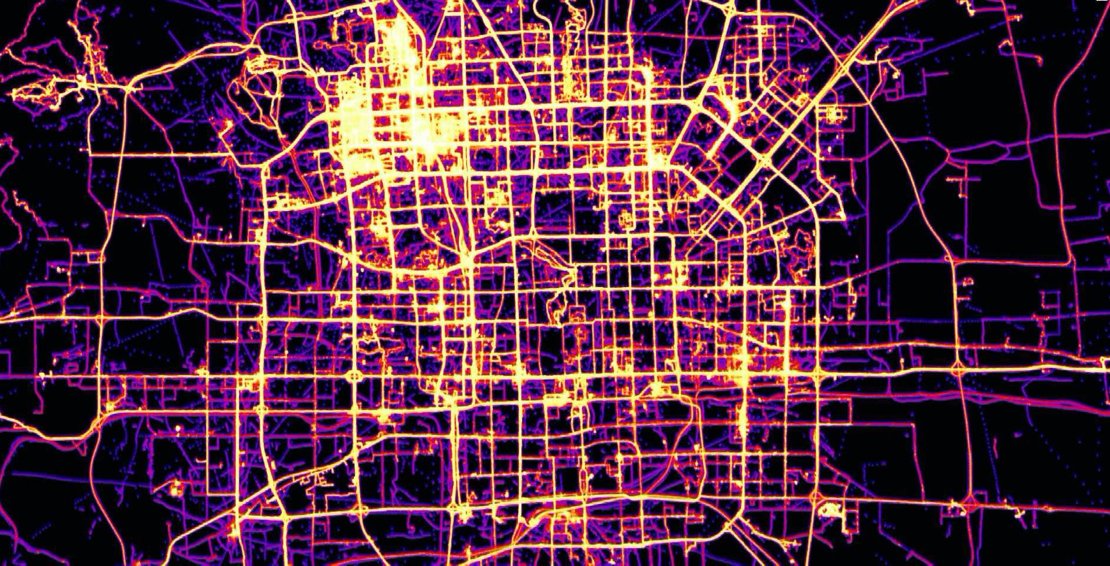
Image credits: GeoWave
{kind=link}
PostGIS is known for extending PostgreSQL to support spatial data types and queries. If you need a similar functionality on top of large-scale key/value stores, which excel in massive data sets, check out GeoWave. GeoWave adds support for geographic objects, geospatial operators, and multi-dimensional indexing capabilities to several existing key/value stores. It provides Map-Reduce input and output formats for distributed geospatial data processing and analysis, as well as a GeoServer plugin to share and visualise data through OGC services. Some nice screenshots of example applications are available here.
Recent Major Releases
- GeoMesa: Large-scale distributed geospatial querying and analytics
3.0.0 (2020/06/26) - GeoPandas: Geospatial operations in pandas
0.8.0 (2020/06/24) - Apache Spark: Distributed general-purpose cluster-computing framework
3.0.0 (2020/06/06) - FlatGeobuf: Performant binary encoding for geographic data
3.3.0 (2020/06/01)
the "Big" Picture

Moreno-Martínez et al. (2020) present a HIghly Scalable Temporal Adaptive Reflectance Fusion Model (HISTARFM) algorithm to combine multispectral images of different sensors to reduce noise and produce gap-free high resolution (30 m) observations at continental scale. It also enables reliable estimation of the uncertainty associated with the final reflectance estimates. Implemented in the Google Earth Engine (GEE), the method allows processing of 120 gigapixels of Landsat imagery for the continental U.S. in 2 days.