Greetings from the Big Geodata Newsletter!
In this issue you will find information on Zarr + STAC for combining data storage and discovery, Icechunk 1.0 as a production-ready cloud-native array storage engine, NVIDIA’s 7 drop-in replacements to accelerate Python data science workflows, the Global Food Twin for modelling worldwide food production and trade, and a new 30 m resolution global grassland productivity dataset providing detailed Gross Primary Productivity maps. This edition also features a user story from our Geospatial Computing Platform on an operational approach to SAR feature extraction for machine learning.
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Zarr + STAC: Bringing Together Data Storage and Discoverability
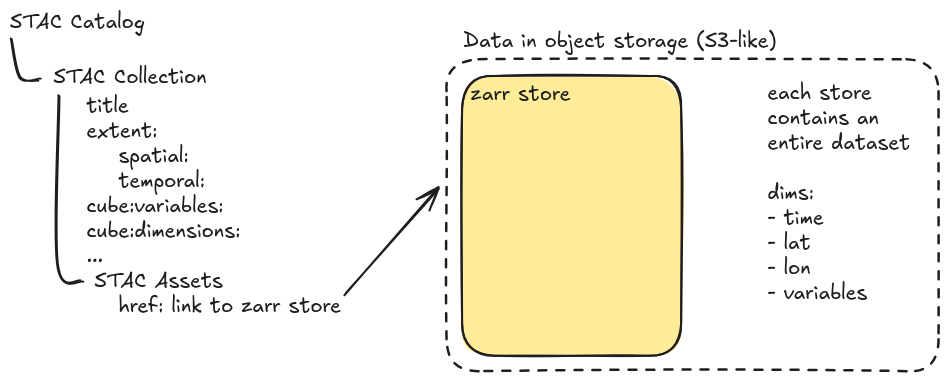
Image credits: Element 84
{kind=link}
Zarr and STAC serve different but complementary roles in the geospatial data ecosystem. Zarr is a cloud-native format for chunked, compressed N-dimensional arrays, optimized for efficient data storage and retrieval from object stores like S3 or Azure Blob. STAC (SpatioTemporal Asset Catalog), on the other hand, is a standard for indexing and discovering spatial-temporal datasets, often used to catalog imagery and other geospatial assets. A key benefit of combining these tools lies in balancing discoverability and efficient data access. While STAC enables users to find datasets of interest via searches on time and location, Zarr enables seamless inside-batch and chunk-level access once a dataset is identified. For data producers, several integration patterns are emerging:(1) Link a single large Zarr store to a STAC collection, (2) Expose nested Zarr groups via STAC metadata, (3) Or use multiple smaller Zarr stores to enhance modularity and clarity. This hybrid approach works well for aligned data cubes (e.g., climate or model outputs). For unaligned scene-based data, STAC with Cloud-Optimized GeoTIFFs (COGs) may still be the better convention.
Learn more about how Zarr and STAC complement each other here.
Icechunk 1.0: Production-Grade Cloud-Native Array Storage
Image credits: Earthmover Blog
A year after its initial preview, Icechunk 1.0 has reached a stable, production-ready milestone. Developed by Earthmover, this open-source storage engine extends the familiar Zarr format to support database-style operations, offering native transaction support and serializable isolation for array-based data in cloud object storage environments. Icechunk enables safe parallel read/write access during analytics or machine learning workflows. It introduces version control features, such as snapshots, branching, and tagging, without duplicating data, thanks to efficient versioning that only writes diffs. Built in Rust with a Python interface, the system supports high-throughput I/O, automatically leveraging cloud storage performance for demanding workloads. Key enhancements in version 1.0 include scalable manifest splitting, enabling management of data with millions of chunks; distributed write support (e.g., via Dask or Xarray); conflict detection and resolution; and data expiration and garbage collection to control storage growth. Icechunk preserves the Zarr model while offering powerful transactional and performance upgrades, positioning itself as a robust foundation for analysis-ready, cloud-native array storage.
Explore Icechunk 1.0 and get started with cloud-native array storage here. Access the Icechunk open source repository and documentation here.
7 Drop-In Replacements to Instantly Speed Up Your Python Data Science Workflows
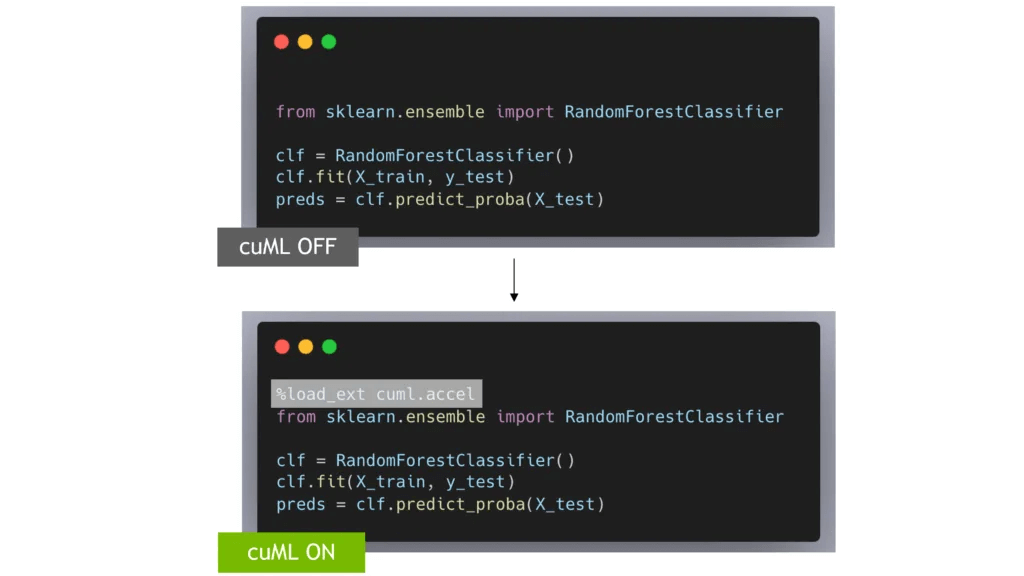
Image credits: NVIDIA Technical Blog
If you’ve ever hit performance limits in a pandas or scikit-learn workflow on a large dataset, NVIDIA’s new guide offers a solution leveraging your GPU. The blog post highlights seven drop-in GPU-accelerated replacements that provide significant speedups with minimal to no changes to your existing code. You can start by using cudf.pandas to accelerate pandas operations, simply adding %load_ext cudf.pandas at the top of your script, and your dataframe code runs on the GPU. Polars users can speed up processing even further by using .collect(engine="gpu") to tap into the Polars GPU engine backed by cuDF. On the machine learning side, cuML accelerates scikit-learn workflows with the %load_ext cuml.accel command, allowing you to train models like RandomForestClassifier on the GPU without changing your Python code. Additional tips include accelerating computationally intensive tasks such as t-SNE, UMAP, HDBSCAN clustering, and graph analytics via GPU-optimized versions like cuML and cuGraph. Overall, this guide empowers Python users to scale workflows efficiently—whether working with CSVs, performing advanced analytics, or training machine learning models—by harnessing GPU power without disrupting existing codebases.
Explore the full guide to turbocharge your Python workflows here. Learn more about RAPIDS libraries like cuDF, cuML, and cuGraph here.
Global Food Twin: A Planet-Wide Digital Double of Our Food System
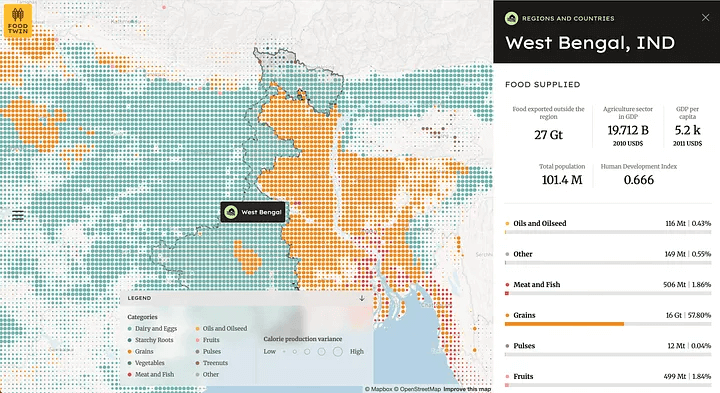
Image credits: Earth Genome
The Global Food Twin, a collaboration between Earth Genome and Better Planet Laboratory, offers a comprehensive, open-source model of global food production, transportation, and consumption patterns. Extending earlier U.S.-focused efforts, this initiative now represents food flows across 3,787 subnational regions in 240 countries, integrating a mix of crop yields, population demand, dietary data, and multi-modal trade pathways including land, sea, and rail. The model quantifies dependencies in the food system, revealing that just 1.2% of regions account for 50% of global grain production, underscoring vulnerability to localized disruptions. Trade concentration is significant too: a small set of bilateral flows dominates global food movement. For instance, Brazil-China and the U.S.-China corridors contribute nearly 7-8% of total trade volume. Designed to support resilience planning and research, the Global Food Twin is fully open: it includes the web app, underlying datasets, and modeling code. This tool enables stakeholders ranging from policymakers to aid organizations to simulate scenarios, predict impacts and build more robust food systems in an ever-changing climate.
Explore the Global Food Twin and access data and insights here. Browse the data and model suite on Source Coop here.
Upcoming EVENTS
- CRIB Training: Publishing Research Data with fairly Toolset
ITC, 26 September 2025 - Big Data from Space 2025
Riga, Latvia, 29 September - 3 October 2025 - SURF Network and Cloud Event,
Hilversum, 30 September 2025 - Zarr Summit
Rome, 13 – 17 October 2025 - STAC Community Sprint 2025
Rome, 14 – 16 October 2025 - National Open Science Festival 2025
Groningen, 24 October 2025 - Research Software Support Training
eScience Center, Amsterdam, 5 - 19 November 2025 - Intermediate Research Software Development with Python
eScience Center, Amsterdam, 28 October - 2 December 2025
The "Big" Picture
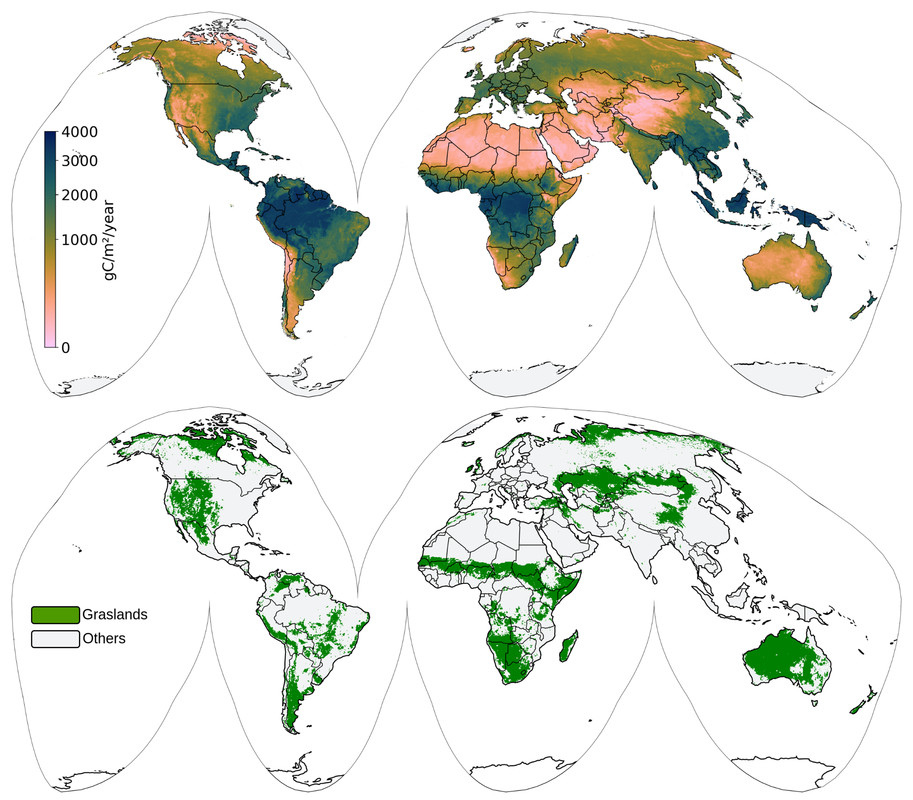
Image credits: Isik et al., 2025
A recent study has released a global, bimonthly Light Use Efficiency (LUE)-based Gross Primary Productivity (GPP) dataset for grasslands at 30 m resolution, covering the years 2000–2022. This dataset represents a significant improvement in ecological monitoring because it transforms an immense 400 TB Landsat archive, together with MODIS surface temperature data and CERES PAR inputs, into accessible, high-quality productivity maps without compromising spatial detail. The dataset was generated using a biome-adjusted LUE model with a constant maximum LUE factor and validated against data from 527 eddy covariance flux towers, achieving R² values between 0.48–0.71 and RMSE below approximately 2.3 gC m⁻² d⁻¹. Specifically for grasslands, validation with 92 flux towers showed R² between 0.51–0.70, with RMSE under 2 gC m⁻² d⁻¹, highlighting its performance across diverse ecosystems. Available as both bimonthly and annual GPP maps in Cloud-Optimized GeoTIFF format (~23 TB total), these data are openly licensed and accessible through SpatioTemporal Asset Catalog (STAC) and Google Earth Engine, enabling scalable analysis for trends, land degradation, and greenhouse gas modeling.
Explore the global grassland GPP dataset and documentation here. Access the STAC collection and download options here.
Isik, M. S., Parente, L., Consoli, D., Sloat, L., Mesquita, V. V., Ferreira, L. G., Sabbatini, S., Stanimirova, R., Teles, N. M., Robinson, N., Costa, C., Junior, & Hengl, T. (2025). Light use efficiency (LUE) based bimonthly gross primary productivity (GPP) for global grasslands at 30 m spatial resolution (2000–2022). PeerJ, 13, e19774. https://doi.org/10.7717/peerj.19774