Greetings from the Big Geodata Newsletter!
In this issue you will find information on managing large-scale geospatial data using the new Microsoft Planetary Computer Pro, the new fully open-source release of cuPyNumeric, accelerating Apache Parquet scans on Apache Spark using GPUs, Obstore - a solution for high-throughput I/O in cloud object storage, and OpenspaceGlobal, which maps urban open spaces across 169 megacities. This edition also features a user story from our Geospatial Computing Platform on the evaluation and improvement of the Copernicus HR-VPP product for crop phenology monitoring.
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Microsoft Planetary Computer Pro: Managing Geospatial Data at Scale
Image credits: Microsoft, 2025
Microsoft Planetary Computer Pro is now in public preview, offering a cloud-native platform for managing, analyzing, and sharing geospatial data. Built on Azure, it enables organizations to handle large-scale geospatial workloads efficiently. The platform introduces GeoCatalog, a managed resource that organizes datasets using the SpatioTemporal Asset Catalog (STAC) specification, ensuring interoperability and streamlined data management. It supports ingestion of various data types, including Cloud Optimized GeoTIFFs (COGs) and data cubes, with built-in transformation pipelines for cloud optimization. Users can interact with their data through intuitive REST APIs, a web-based Data Explorer, and integrations with tools like ArcGIS Pro. Security is maintained via Microsoft Entra ID and Azure RBAC, providing controlled access and compliance. Currently available in selected Azure regions, Planetary Computer Pro caters to sectors such as scientific research, agriculture, and energy, facilitating applications like precision farming, climate risk assessment, and environmental monitoring.
Learn more about Microsoft Planetary Computer Pro and its capabilities here. Read the announcement in the public preview here.
NVIDIA cuPyNumeric: Now Fully Open Source with PIP and HDF5 Support

Image credits: NVIDIA, 2025
NVIDIA cuPyNumeric is a distributed, accelerated drop-in replacement for NumPy, built atop the Legate framework. The latest release, version 25.03, introduces several enhancements aimed at improving accessibility and performance. A significant update is the open-sourcing of the entire cuPyNumeric stack, including the Legate framework and runtime layer, under the Apache 2.0 license. This move promotes transparency and encourages community collaboration in the development of high-performance computing tools. Installation has been simplified with the addition of pip support, allowing users to install cuPyNumeric simply using: pip install nvidia-cupynumeric. This complements the existing Conda installation method, making it easier to integrate cuPyNumeric into various workflows and environments. Furthermore, native HDF5 I/O support has been added, facilitating efficient handling of large datasets, which is crucial for scientific computing applications. The library also supports multi-node and multi-GPU configurations, enabling scalable performance across diverse hardware setups.
Explore the full details of cuPyNumeric 25.03 and its capabilities here. Access the official documentation and installation guides here.
Accelerating Apache Parquet Scans on Apache Spark with GPUs
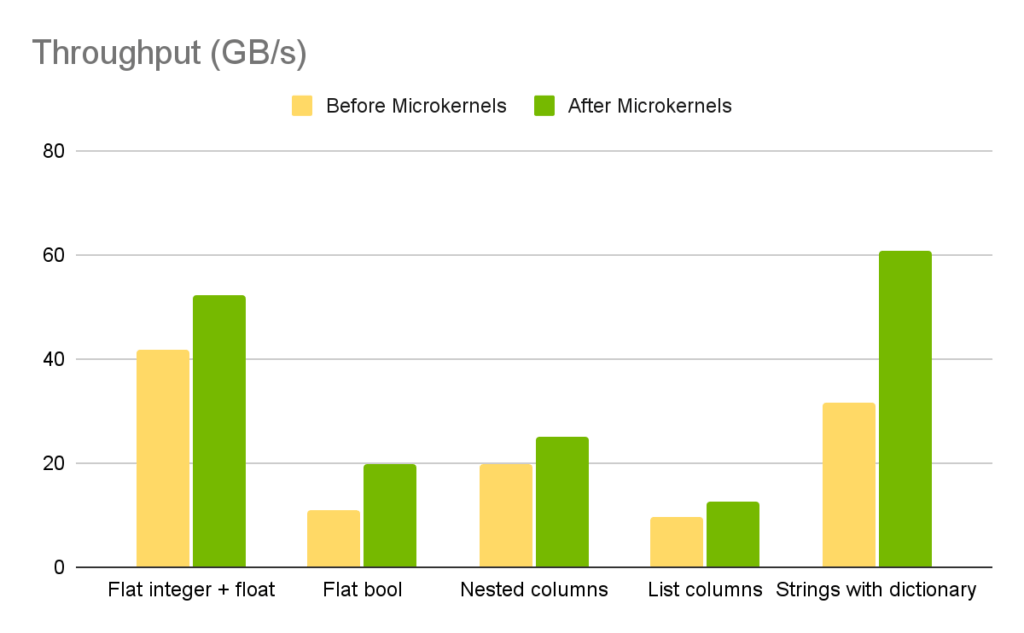
Image credits: NVIDIA, 2025
Apache Spark remains a widely adopted platform for large-scale data processing, but performance bottlenecks often arise during Parquet file scans, particularly when dealing with massive datasets. To address this, NVIDIA introduces an enhancement leveraging GPUs to accelerate Apache Parquet scans within Spark environments. By integrating the NVIDIA RAPIDS Accelerator for Apache Spark, users can offload scan operations from CPUs to GPUs. This significantly reduces I/O latency and improves throughput, especially when working with large Parquet files common in data lakes and cloud-native warehouses. NVIDIA’s testing shows that enabling GPU-based scans speeds up data loading and query execution, without requiring users to rewrite existing Spark code. This performance gain stems from RAPIDS' ability to parse Parquet files directly using cuDF, an accelerated DataFrame library. The feature is now available in RAPIDS Accelerator v24.04 and supports key enhancements like automatic column pruning, predicate pushdown, and efficient buffer management, all optimized for GPU execution.
Learn more about GPU-accelerated Parquet scans on Spark here. Explore the RAPIDS Accelerator for Apache Spark here.
Obstore: A High-Throughput Python Interface for Cloud Object Storage
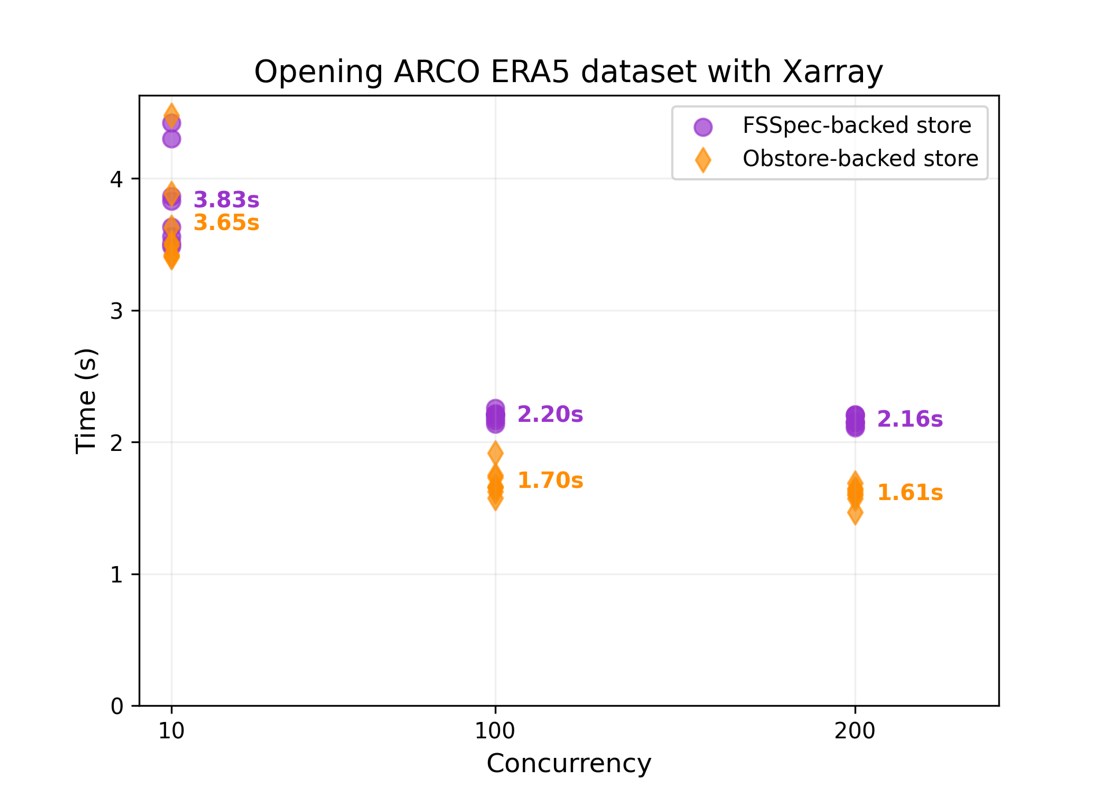
Image credits: Max Jones, GitHub
{kind=link}
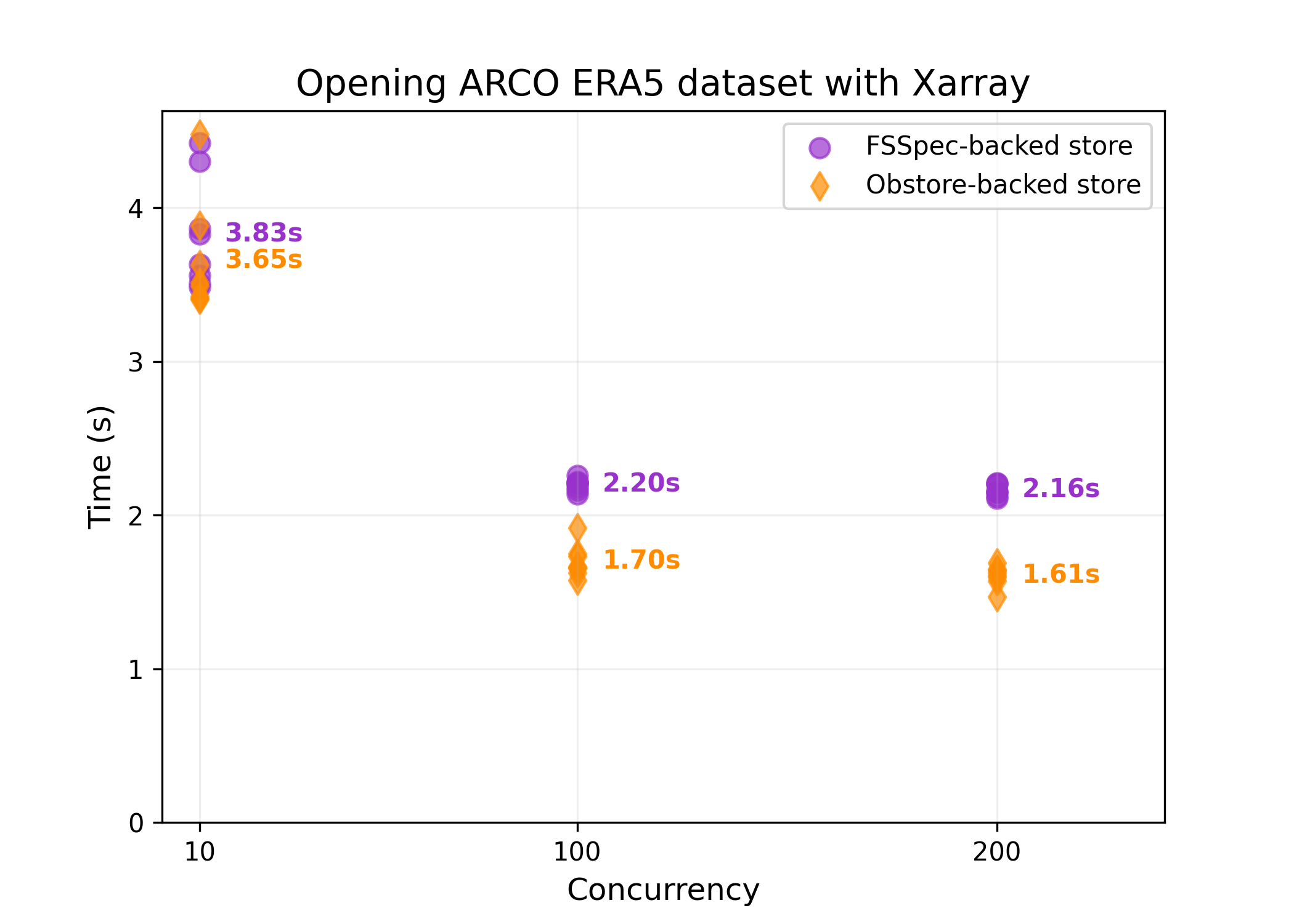
Obstore is a Python library developed by Development Seed that offers a streamlined interface for interacting with various cloud object storage services, including Amazon S3, Google Cloud Storage, and Microsoft Azure Storage. Built with Rust for enhanced performance, Obstore facilitates efficient data operations in Python workflows. Key features of Obstore include, support for both synchronous and asynchronous APIs with full type hinting, streaming downloads and uploads, allowing for configurable chunking and handling of large files without loading entire datasets into memory, integration with fsspec, enabling compatibility with various data processing tools, automatic handling of multipart uploads and credential refresh, simplifying authentication and large data transfers, and optional return of list results in Apache Arrow format for improved performance and memory efficiency. Recent updates have introduced features such as the PlanetaryComputerCredentialProvider, which automates token access and refresh when working with Microsoft's Planetary Computer data.
Learn more about Obstore and its capabilities here.
Upcoming EVENTS
- SURF Training: Introduction to Deep Learning
Amsterdam, 12 June 2025
- Destination Earth User eXchange
Vienna, 25 - 26 June 2025 - Living Planet Symposium 2025
Vienna, 23 - 27 June 2025 - SURF Training: High-Throughput Data Movement and Data Abstraction
Utrecht, 27 June 2025 - Big Data from Space 2025
Riga, 29 September - 3 October 2025
The "Big" Picture

Image credits: Fan et al., 2025
A recent study published in Scientific Data introduces OpenspaceGlobal, a high-resolution urban open space (UOS) dataset covering 169 megacities worldwide. Utilizing deep learning techniques and remote sensing imagery, the researchers developed a 1.19 m resolution map that classifies urban spaces into five categories: parks and green spaces, outdoor sports spaces, transportation spaces, water bodies, and background areas. The team processed over 8.5 terabytes of satellite images and integrated nearly 90 million polygons from crowdsourced geospatial data sources like OpenStreetMap. To address challenges in mapping heterogeneous urban environments, they implemented a tiny-manual annotation strategy, reducing the need for extensive manual labeling. The resulting dataset achieved an overall accuracy of 79.13% and a kappa coefficient of 73.47%, indicating reliable classification performance. OpenspaceGlobal serves as a valuable resource for urban planners, environmental researchers, and policymakers, providing insights into the distribution and characteristics of open spaces in densely populated cities. It supports initiatives aimed at promoting sustainable urban development and enhancing public access to green spaces, aligning with Sustainable Development Goal 11.7.
Explore the OpenspaceGlobal dataset here. Access the full study and supplementary materials here.
Fan, R., Wang, L., Xu, Z., Niu, H., Chen, J., Zhou, Z., Li, W., Wang, H., Sun, Y., and Feng, R. (2025) The first urban open space product of global 169 megacities using remote sensing and geospatial data. Scientific Data, 12(1). doi:10.1038/s41597-025-04924-x