Greetings from the Big Geodata Newsletter!
In this issue, you will find highlights on several exciting developments: the Coalesced Chunk Retrieval Protocol (CCRP), which is redefining cloud-native data access; a new workflow for generating and accessing WorldCereal Geospatial Embeddings; the ASDI Data Explorer and Maxar Open Data Explorer for interactive exploration and visualization of AWS Open Data Program datasets; SedonaDB, an analytical database engine with geospatial capabilities at its core; and TerraMind, a multimodal foundation model for EO developed by IBM, ESA, and Forschungszentrum Jülich.
In this edition, we also bid farewell to Jay Gohil, a key member of the CRIB team whose contributions have been invaluable.
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Redefining Cloud-Native with the Coalesced Chunk Retrieval Protocol

Image credits: Cloud-Native Geospatial, 2025
{kind=link}
The Cloud-Native Geospatial community has introduced the Coalesced Chunk Retrieval Protocol (CCRP), a new approach on how cloud platforms handle large, chunked geospatial datasets. Traditionally, accessing cloud-optimized data, such as rasters or multidimensional datacubes, involves issuing thousands of small HTTP range requests, creating network overhead and slowing analytics. CCRP solves this by allowing clients to send a single coalesced request that lists all the needed chunks across space, time, or variable dimensions and receive them together in one efficient stream. This approach dramatically reduces latency, bandwidth consumption, and API call volume, while maintaining fine-grained, on-demand data access. By decoupling logical data queries from physical storage layouts, CCRP lets users focus on "what" data they need, not "how" it's chunked or stored. Importantly, CCRP is backward compatible, designed to work as a proxy layer that can sit in front of existing COGs, Zarr, or Parquet datasets without major reformatting. The result is faster queries, smoother scaling, and cheaper cloud operations, which are key advantages for data providers and analysts alike.
Learn more about the Coalesced Chunk Retrieval Protocol here.
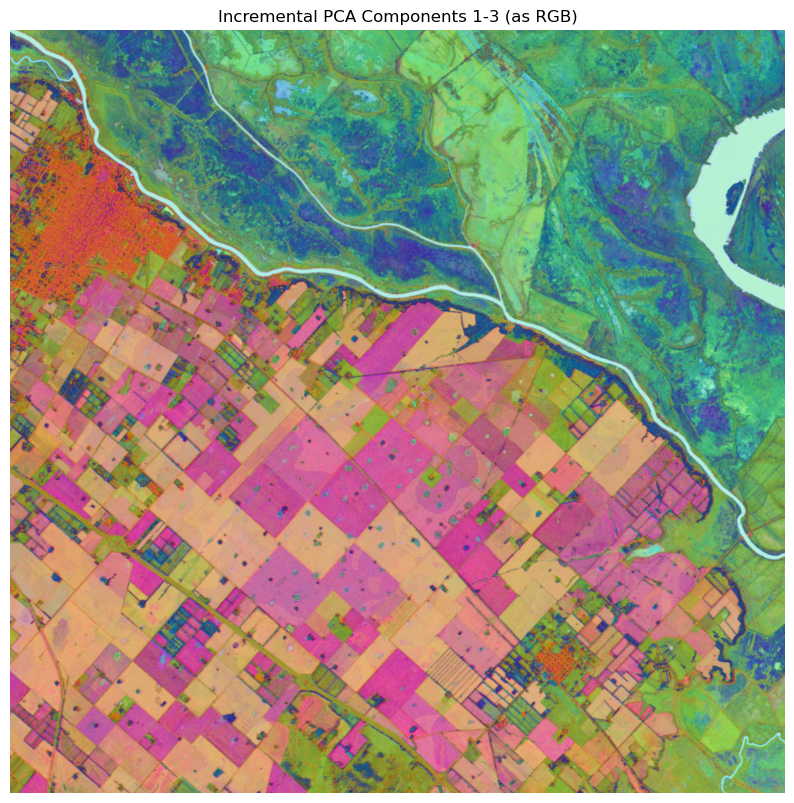
A New Workflow to Generate and Access WorldCereal Geospatial Embeddings

Image credits: ESA WorldCereal, 2025
{kind=link}
The ESA's WorldCereal initiative, a global system for crop type and agricultural monitoring, has introduced a new geo-embeddings workflow that extends its platform's analytical capabilities. WorldCereal leverages EO data and the Presto Geospatial Foundation Model to generate dense vector embeddings, numerical representations that capture spatial, temporal, and spectral patterns within satellite imagery. These embeddings form the foundation of WorldCereal's crop mapping and land cover classification products. With the newly released workflow, users can now generate and access these embeddings directly through an open-source, modular pipeline. The workflow provides detailed documentation and example notebooks, enabling users to specify geographic regions and time periods, run the embedding generation process, and retrieve high-dimensional feature vectors instead of predefined map outputs. By making its embedding infrastructure openly available, WorldCereal fosters greater transparency and allows researchers, developers, and data scientists to build custom models for tasks such as land cover classification, anomaly detection, and agricultural monitoring, while ensuring compatibility with evolving EO foundation models.
Read more about ESA WorldCereal Geo-embeding Workflow here. Access the demonstration notebook here.
Interactive Access and Visualization of AWS Open Data Program Datasets
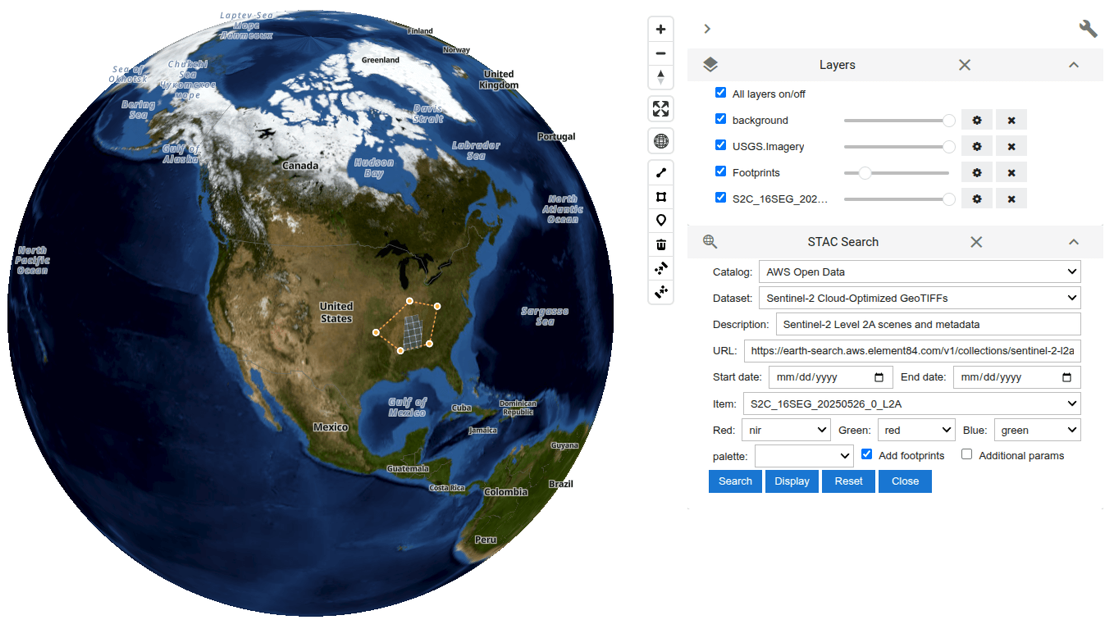
Image credits: AWS, 2025
{kind=link}
Amazon's AWS Open Data Program provides a vast repository of publicly accessible, cloud-optimized datasets designed to accelerate research, innovation, and decision-making across a wide range of fields. Within this ecosystem, two new interactive tools made available recently to facilitate data exploration: the ASDI Data Explorer and the Maxar Open Data Explorer. The ASDI Data Explorer, powered by the Amazon Sustainability Data Initiative (ASDI), enables users to interactively browse environmental datasets with spatial and temporal filters, perform STAC-based searches, and visualize data directly on interactive maps. Built using the Leafmap and deployed through the Solara web framework on Hugging Face Spaces, it offers a user-friendly interface for accessing extensive environmental data collections. Complementing this, the Maxar Open Data Explorer specializes in high-resolution satellite imagery for disaster response and humanitarian support, allowing users to explore event-based imagery, compare pre- and post-event conditions, and assess damage through interactive map visualizations. Together, these two tools showcase how open geospatial data delivers timely insights and informed decision-making through accessible, cloud-native platforms.
Try ASDI Data Explorer here, and Maxar Open Data Explorer here. Learn more about both tools here.
SedonaDB: An analytical database engine with geospatial as a first-class citizen
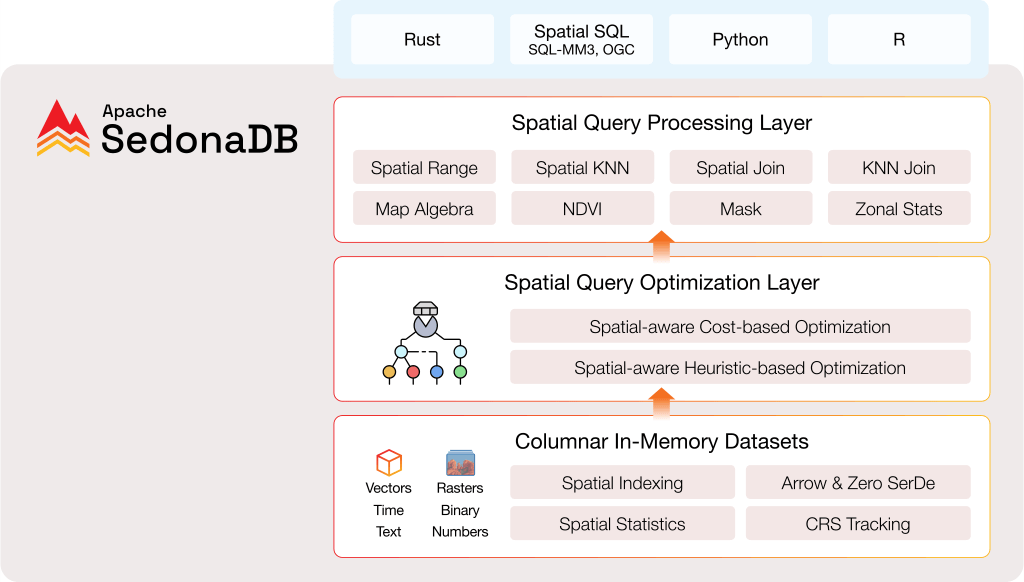
Image credits: Apache Sedona, 2025
{kind=link}
Apache Sedona has introduced SedonaDB, an open-source, single-node analytical database engine that prioritizes geospatial data as a first-class citizen. Developed as a subproject of Apache Sedona, SedonaDB is designed to deliver high-performance spatial analytics for small-to-medium datasets, offering a lightweight alternative to distributed systems like Sedona Spark, Sedona Flink, and Sedona Snowflake. Written in Rust, SedonaDB boasts a columnar in-memory architecture optimized for spatial operations, featuring built-in spatial indexing, coordinate reference system (CRS) tracking, and support for Arrow format with zero serialization overhead. It provides a comprehensive suite of spatial functions, including spatial range queries, K-nearest neighbors (KNN) joins, map algebra, and zonal statistics. The engine supports multiple interfaces, including Python, SQL, R, and Rust, allowing developers to leverage familiar tools for geospatial data analysis. SedonaDB's spatial-aware query optimization and adaptive join strategies ensure efficient processing of complex spatial queries. Benchmark tests have demonstrated SedonaDB's superior performance in geometric computations and complex spatial joins compared to other analytical engines like DuckDB and GeoPandas.
Read more about Apache SedobaDB here. Check quick start for Python here and additional development guides here.
Upcoming EVENTS
- Zarr Summit
Rome, 13 - 17 October 2025 - STAC Community Sprint 2025
Rome, 14 - 16 October 2025 - National Open Science Festival 2025
Groningen, 24 October 2025 - Intermediate Research Software Development with Python
eScience Center, Amsterdam, 28 October - 2 December 2025 - Big Geodata Talk: Geofoundation Models - Unlocking the Power of GeoAI
ITC or Online, 5 November 2025 - Research Software Support Training
eScience Center, Amsterdam, 5 - 19 November 2025 - Training Workshop: Publishing Research Data with fairly Toolset
ITC, 27 November 2025
The "Big" Picture
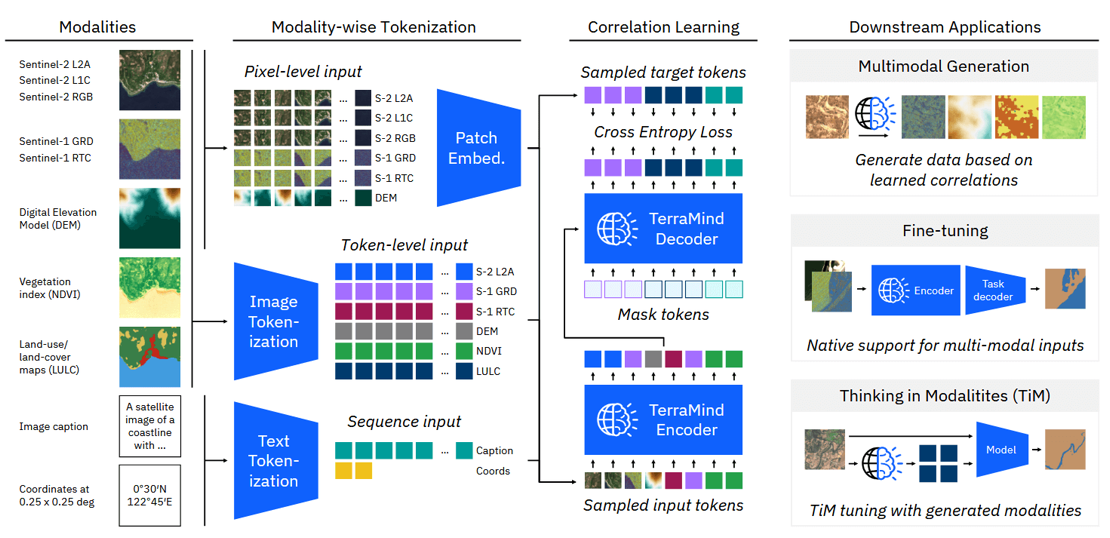
Image credits: Jakubik et al., 2025
TerraMind is a multimodal foundation model for EO, developed by IBM, ESA, and Forschungszentrum Jülich. It is the first "any-to-any" generative model in the domain, capable of translating between various EO modalities, such as optical imagery, radar data, elevation maps, and textual descriptions. Trained on the TerraMesh dataset, which comprises over 9 million globally distributed, spatiotemporally aligned samples across nine core modalities, TerraMind leverages a dual-scale transformer-based encoder-decoder architecture. This design enables it to process both pixel-level and token-level data simultaneously, capturing fine-grained spatial details and high-level contextual information. A notable feature of TerraMind is its "Thinking-in-Modalities" (TiM) tuning approach, allowing the model to self-generate additional training data from other modalities, thereby enhancing its performance on EO tasks. Empirical evaluations demonstrate that TerraMind outperforms existing geospatial foundation models on benchmark datasets like PANGAEA. The model is lightweight and efficient, requiring significantly less computational resources compared to traditional models, making it suitable for deployment at scale. Researchers and developers can access TerraMind's model weights and fine-tuning toolkit on Hugging Face.
Read more about TerraMind here. Access TerraMind on Hugging Face here.
J. Jakubik, F. Yang, B. Blumenstiel, E. Scheurer, R. Sedona, S. Maurogiovanni, J. Bosmans, N. Dionelis, V. Marsocci, N. Kopp, R. Ramachandran, P. Fraccaro, T. Brunschwiler, G. Cavallaro, J. Bernabe-Moreno, N. Longépé (2025) TerraMind: Large-Scale Generative Multimodality for Earth Observation. arXiv. doi:10.48550/arXiv.2504.11171.